이 번에 리뷰하게 된 책은 스파크 완벽 가이드 입니다.
아파치 스파크 창시자인 마테이가 쓴 스파크 바이블이라고 할 수 있습니다. 친절한 기본부터 꼼꼼한 심화까지 잘 구성되어 있어 입문용으로도 좋고, 두고두고 곁에 두고 필요할때 꺼내어 참고 할 수 있는 참고용으로 참 좋습니다.
빅데이터에 입문하는 분과 데이터 엔지니어 및 과학자 분의 소중한 시간을 크게 절약해 줄 책입니다.
스파크 바이블이라 할만큼 그 내용이 방대합니다. 페이지는 약 700페이지가 넘고 매우 두껍습니다. 그만큼
상세한 내용을 다루고 있습니다.
그럼 이책에 대해서 간단히 살펴보겠습니다.
Part1 빅데이터와 스파크 간단히 살펴보기
Part1 에서는 아파치 스파크에 대해서 살펴봅니다. 아파치 스파크는 통합 컴퓨팅 엔진이며 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합입니다. 스파크는 가장 활발하게 개발되고 있는 병렬 처리 오픈소스 엔진이며 빅데이터에 관심 있는 여러 개발자와 데이터 과학자에게 표준 도구가 되어가고 있습니다.
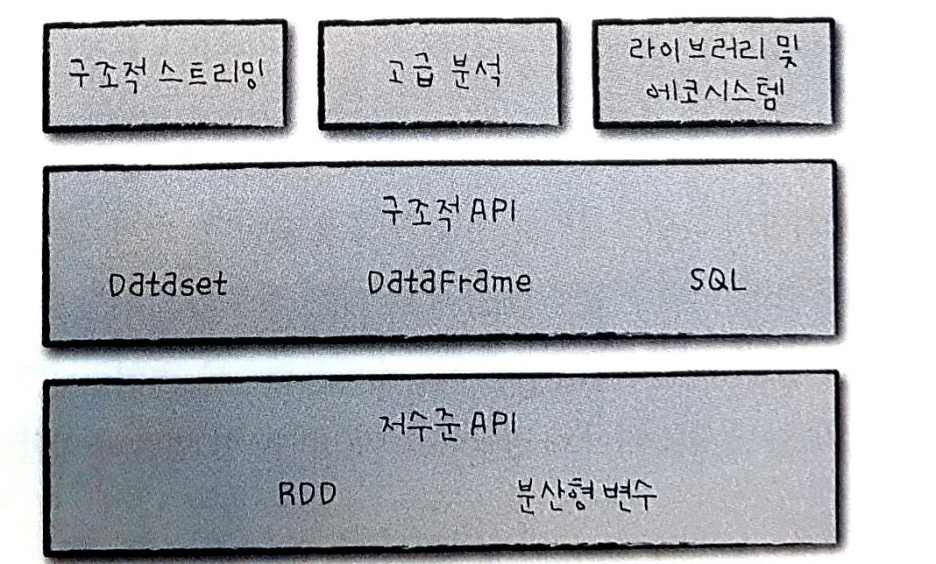
Part2 구조적 API :DataFrame, SQL, Dataset
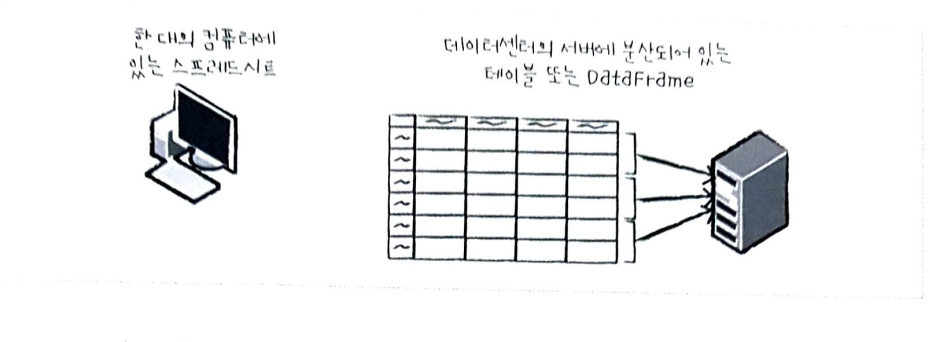
2부에서는 스파크의 구조적 API에 대해서 살펴봅니다. 구조적 API는 비정형 로그 파일부터, 반정형 CSV 파일, 매우 정형적인 파케이(Parquest)파일까지 다양한 유형의 데이터를 처리 할수 있습니다.
Part3 저수준 API
2부에서는 스파크의 구조적 API를 알아보았습니다. 대부분의 상황에서는 구조적 API를 사용하는 것이 좋습니다. 그러나 비지니스나 기술적 문제를 고수준(high-level) API를 사용해 모두 처리 할 수 있는 것은 아닙니다. 이런 경우 스파크의 저수준 API를 사용해야 할 수도 있습니다. 스파크의 저수준 API는 RDD, SparkContext 그리고 어큐물레이터와 브로드캐스트 변수 같은 분산형 공유 변수 등을 의미합니다. 3부에서는 저수준 API와 사용 방법을 알아봅니다.
Part4 운영용 애플리케이션
4부에서는 물리적으로 분리된 서버들을 논리적으로 엮어 거대한 컴퓨팅 파워를 만들어주는 클러스트 매니저를 스파크에서 활용하는 방법을 알아봅니다. 그리고 가장 궁금한 내용일 수도 모니터링과 성능 튜닝에 대한 실무적인 접근법에 대해서 알아봅니다.
Part5 스트리밍
많은 기업이 스트리밍 데이터를 처리하기 위해 아파치 스파크의 스트리밍 기능을 사용합니다. 구조적 API기반의 구조적 스트리밍은 스트리밍 처리에 필요한 복잡한 요건을 자체적으로 해결해주는 아주 영리한 도구입니다.
5부에서는 스트림 처리의 개요를 알아보고 스파크가 처리 요건을 어떻게 자동화하는지 알아보겠습니다.
Part6 고급 분석과 머신러닝
6부에서는 스파크에서 제공하는 고급 분석 및 머신러닝을 위한 다양한 API를 좀 더 자세히 설명합니다. 스파크는 대용량 데이터에 대한 SQL 분석과 스트림 처리 외에도 통계 분석, 머신러닝 그리고 그래프 분석을 지원하며 이러한 고급 분석을 수행하는데 필요한 일련의 작업 과정도 제공합니다.
Part7 에코시스템
7부에서는 많은 스파크 사용자가 선택하는 파이썬과 R의 언어적 특성을 상세히 살펴봅니다. 그리고 스파크가 가지고 있는 비기술적 장점에 대해서도 가볍게 알아봅니다.
이 책은 스파크의 전반적인 구조와 주요 API에 대해서 자세히 설명하고 있습니다.
스파크의 기본 아키텍처부터 구조적 API의 내용 그리고 스파크 2.x의 새로운 특징들을 설명하였습니다.
스파크를 처음 접하는 입문자 스파크로 빅데이터 플랫폼을 운용하는 데이터 엔지니어, 스파크 애플리케이션을 개발하는 디벨로퍼 그리고 스파크로 데이터 전처리를 수행하는 데이터 분석가 모두에 추천합니다.






![[상세이미지]스파크 완벽 가이드_733.jpg](https://www.hanbit.co.kr/data/editor/20181203135359_prpkmeaf.jpg)