




머신러닝이 본격적으로 많은 기업에서 활용되기 시작하면서 최근 몇 년 간 MLOps의 수요도 덩달아 높아지고 있다. 머신러닝쪽은 현재 업무와 큰 연관성이 없어 MLOps를 배워야 할 절실한 이유가 있는 것은 아니지만, 올 해 초 쿠버네티스 페이스북 그룹에 조훈님이 올려주신 “2022년 쿠버네티스 표준 아키텍처(아키텍처에 대한 설명은 여기)” 에 한 꼭지로 MLOps도구인 Kubeflow가 올라와 있어 관심을 갖고 있던 분야라 신청해보았다.
MLOps란?
MLOps란 머신러닝과 운영(Machine Learning Operations)의 합성어로, ModelOps와 혼용되는 개념이기도 하다(ModelOps는 머신러닝 뿐만 아니라 다른 종류의 모델도 포함하는 MLOps보다 포괄적 개념이다). MLOps의 핵심은 머신러닝 모델의 생애주기 관리를 표준화하고 간소화하는 것이다. 이 MLOps는 AIOPs와 혼동될 수 있으나 AIOps는 인공지능을 이용하여 운영상의 과제들을 해결하는 데에 초점을 맞추고 있다. 즉, AIOps는 머신러닝을 포함한 인공지능을 ‘수단’으로서 활용하며, MLOps는 ‘머신러닝의 운영 효율화' 자체가 그 목적으로, MLOps 도입 가이드 책에서는 다루지 않는다.
‘MLOps 도입 가이드’ 리뷰
MLOps 도입 가이드는 총 세 개 파트로 나뉘어있다. 가장 먼저 MLOps의 개념과 필요성을 다룬 다음, MLOps를 어떻게 적용하는지에 대해 다루게 된다. 그리고 마지막으로는 마케팅 추천 엔진이나 소비 예측 들 MLOps가 활용되는 실제 사례를 다루고있다.
MLOps 도입 가이드를 읽으며 느낀 점은 MLOps가 단어 뿐만 아니라 업무 내용도 DevOps와 꽤나 유사하다는 점이다. 책의 도입 부분에서 머신러닝의 생애 주기를 다루고 있는데, “비즈니스 목표 정의 → 데이터에 대한 접근, 이해, 정리 → 머신러닝 모델 생성 → 머신러닝 모델 배포 (반복)”이라고 적혀있는 다이어그램을 보고 데이터를 다루고 있다는 점은 상이하지만 머신러닝 모델을 애플리케이션으로 치환하면 목표 정의와 배포, 평가를 반복하는 것이 DevOps와 꽤나 유사하다고 느꼈는데, 바로 다음페이지에서 MLOps 개념의 많은 부분은 DevOps에서 차용한 것이라고 해서 바로 납득했다 ㅎㅎ 다만, 책에 의하면 머신러닝 모델은 일반적인 애플리케이션보다 동적이기 때문에 DevOps 엔지니어를 바로 MLOps에 투입할 수 없다고 설명하고 있다.
이러한 동적이고 복잡도가 높은 MLOps의 업무를 어떻게 적용하는지에 대한 부분은 파트2에서 주로 나오게 되는데, 아직 주니어 데브옵스 엔지니어로서 DevOps업무와 가장 큰 차이가 있는 부분을 고르자면 데이터 거버넌스 파트이다. GDPR이나 GxP 등 개인정보 보호를 포함해 데이터를 다룰 때 각국의 규칙을 파악해 적용해야 한다는 부분이 인상 깊었다.
마지막 파트에서는 MLOps의 실제 사례를 다루고 있는데, 각 사례별로 전체적인 흐름을 제시하고 있다. 이 책의 제목이 “MLOps 도입 가이드"인 만큼, 특정 MLOps 툴이나 스텝별 프로세스를 상세히 알려주는 튜토리얼을 원하는 사람보다는, MLOps 업무의 전체적인 흐름과 MLOps 업무에서 중요한 부분을 파악하고싶은 머신러닝(혹은 MLOps) 엔지니어 직무를 희망하는 사람이나, 사내에서 MLOps 도입 검토를 맡게 된 사람에게 권하고 싶은 책이다.
“한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
4.7점 (15명)
좋아요 : 9
MLOps의 개념부터 도입과 활용까지,
성공적인 머신러닝 운영화를 위한 실용 가이드!
오늘날 데이터 사이언스와 AI는 IT 분야뿐 아니라 제조, 구매, 유통, 마케팅, 반도체, 자동차, 식품 등 산업 전 분야에 걸쳐 기업 생존의 필수 요소로 인식되어 경쟁적으로 도입되고 있다. 이러한 데이터 사이언스와 AI 프로젝트의 핵심에 MLOps가 놓여 있다.
이 책은 비즈니스 환경에서 머신러닝 적용 실무를 담당하는 데이터 분석 팀 또는 IT 운영 팀의 관리자들을 대상으로 한다. MLOps가 새로운 영역이라는 점을 감안하여, MLOps 환경을 성공적으로 구축하기 위한 가이드 역할을 제대로 할 수 있도록 머신러닝 전문가 9명(데이터이쿠)이 조직적 이슈부터 기술적 이슈까지 꼼꼼하게 다루었다.
- MLOps 핵심 개념: MLOps를 성공적으로 실행하기 위한 원칙과 구성 요소, 이해관계자들의 역할과 책임
- MLOps 적용 방법: 머신러닝 모델 생애주기 다섯 단계에 따라 MLOps 프로세스를 도입하는 방법 소개
- MLOps 실제 사례: MLOps의 실제 구축 형태와 그 의미를 알 수 있도록 대표적인 비즈니스 활용 사례들 제시


PART 1 MLOps 개념과 필요성
CHAPTER 1 왜 지금이고 도전 과제는 무엇인가
1.1 MLOps와 도전 과제 정의하기
1.2 리스크를 경감하기 위한 MLOps
1.3 확장을 위한 MLOps
1.4 마치며
CHAPTER 2 MLOps 이해관계자들
2.1 직무 전문가
2.2 데이터 과학자
2.3 데이터 엔지니어
2.4 소프트웨어 엔지니어
2.5 DevOps
2.6 모델 리스크 관리자/감리인
2.7 머신러닝 아키텍트
2.8 마치며
CHAPTER 3 MLOps의 핵심 기능
3.1 머신러닝 입문
3.2 모델 개발
3.3 제품화 및 배포
3.4 모니터링
3.5 반복 및 생애주기
3.6 거버넌스
3.7 마치며
PART 2 MLOps 적용 방법
CHAPTER 4 모델 개발
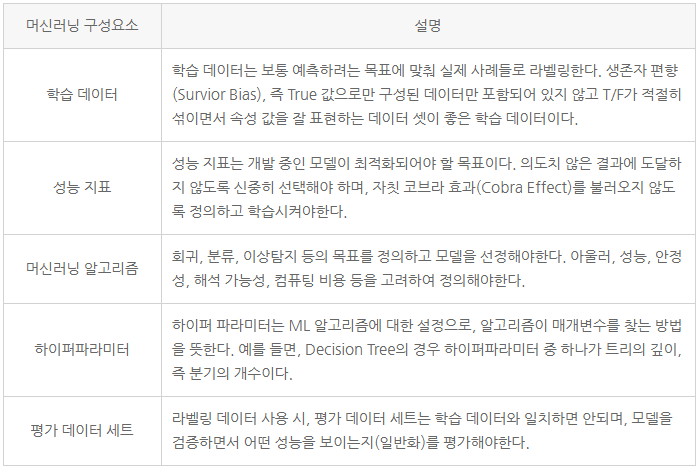
4.1 머신러닝 모델이란?
4.2 데이터 탐색
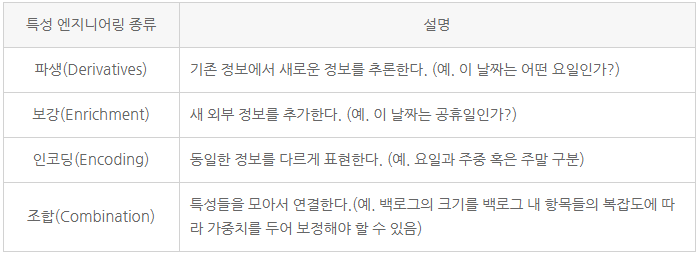
4.3 특성 엔지니어링 및 특성 선택
4.4 실험
4.5 모델 평가 및 비교
4.6 버전 관리 및 재현 가능성
4.7 마치며
CHAPTER 5 상용화 준비
5.1 실행 환경
5.2 모델 리스크 평가
5.3 머신러닝에 대한 품질 검증
5.4 테스트에 대한 핵심 고려 사항
5.5 재현 가능성과 감사 가능성
5.6 머신러닝 보안
5.7 모델 리스크 경감
5.8 마치며
CHAPTER 6 상용 배포
6.1 CI/CD 파이프라인
6.2 머신러닝 아티팩트 개발
6.3 배포 전략
6.4 컨테이너화
6.5 배포 확장
6.6 요구사항과 도전 과제
6.7 마치며
CHAPTER 7 모니터링과 피드백 루프
7.1 모델을 얼마나 자주 재학습시켜야 할까?
7.2 모델 성능 저하
7.3 드리프트 감지
7.4 피드백 루프
7.5 마치며
CHAPTER 8 모델 거버넌스
8.1 조직에 어떤 거버넌스가 필요한지 누가 결정하는가?
8.2 리스크 수준에 거버넌스 맞추기
8.3 MLOps 거버넌스를 주도하는 현행 규정
8.4 AI 관련 규정의 최신 동향
8.5 책임 있는 AI의 등장
8.6 책임 있는 AI의 핵심 요소
8.7 MLOps 거버넌스 템플릿
8.8 마치며
PART 3 MLOps 실제 사례
CHAPTER 9 소비자 신용 리스크 관리
9.1 배경: 비즈니스 활용 사례
9.2 모델 개발
9.3 모델 편향성에 대한 고려 사항
9.4 상용화 준비
9.5 상용 배포
9.6 마치며
CHAPTER 10 마케팅 추천 엔진
10.1 추천 엔진의 반란
10.2 데이터 준비
10.3 실험 설계 및 관리
10.4 모델 학습 및 배포
10.5 파이프라인 구조와 배포 전략
10.6 모니터링과 피드백
10.7 마치며
CHAPTER 11 소비 예측
11.1 전력 시스템
11.2 데이터 수집
11.3 문제 정의: 머신러닝인가, 머신러닝이 아닌가?
11.4 공간 및 시간 해상도
11.5 구현
11.6 모델링
11.7 배포
11.8 모니터링
11.9 마치며
찾아보기
머신러닝 적용 실무를 담당하는 데이터 분석 팀
또는 IT 운영 팀의 관리자들에게
MLOps 역량을 개발하기 위한
실질적인 통찰과 해결책을 제공한다!
머신러닝 기술은 이론과 학문의 영역에서 ‘현실 세계’의 영역으로 이동하는 전환점에 이르렀다. 전 세계의 모든 서비스와 제품에 머신러닝 기술을 적용해보려는 시도가 이어지고 있다. 이러한 변화가 흥미롭기는 하지만, 머신러닝 모델의 복잡한 특성과 현대적인 조직의 복잡한 구조를 조합하는 대단히 도전적인 과제다.
조직이 머신러닝을 실험실 수준에서 상용 환경으로 확대 적용할 때 겪는 어려움 중 하나는 유지보수다. 기업은 하나의 모델만 다루던 환경에서 수십, 수백 혹은 수천 개의 모델을 다루는 환경으로 어떻게 전환할 수 있을까? 바로 이 지점에서 앞서 언급한 기술적인 복잡성과 비즈니스적 복잡성이 드러나고, MLOps가 필요하다.
MLOps는 기업이 데이터 사이언스와 AI를 더 성공적으로 도입·운영할 수 있는 효과적인 방법론 중 하나다. 이 책을 통해 MLOps 역량을 개발하기 위한 실질적인 통찰과 해결책을 얻길 바란다.
이 책은 크게 3부로 구성되어 있다.
※ 1부_MLOps 개념과 필요성
MLOps라는 주제를 전반적으로 소개한다. MLOps가 어떻게 그리고 어떤 이유에서 원칙이 되었는지, MLOps를 성공적으로 실행하려면 어떤 사람들이 MLOps에 참여해야 하는지, 그리고 어떤 구성 요소가 있는지를 설명하였다.
※ 2부_MLOps 적용 방법
머신러닝 모델 생애주기에 맞춰 모델 개발, 상용화 준비, 상용 환경 배포, 모니터링과 피드백 루프, 모델 거버넌스 등의 순서로 구성하였다. 각 장에서는 일반적인 고려 사항과 함께 MLOps 관련 고려 사항을 다루었다. 특히, 1부 3장에서 가볍게 소개한 주제들을 상세하게 설명한다.
※ 3부_MLOps 실제 사례
오늘날 기업에서 운영하는 MLOps의 모습에 대한 실질적 예시를 제공하여, 독자들이 실제 구축 형태와 그 의미를 이해할 수 있도록 하였다. 등장하는 회사명은 모두 가명이지만, 모든 사례는 실제 기업에서 MLOps와 모델 관리에 대해 겪고 있는 경험을 바탕으로 구성하였다.
추천사
기업 내 다양한 조직에서 폭넓게 활용하기 위해 머신러닝 프로세스에 대한 더 나은 전략과 활성화 방안을 찾고 있다면, 이 책이 정답이다.
_아디 폴락, 마이크로소프트, 수석 소프트웨어 엔지니어
기업 내 모델 배포 프로세스 및 시스템의 구축, 확장, 효율화 및 관리에 대한 탁월한 가이드다.
_파룰 팬디, H2O.ai, 데이터 사이언스 에반젤리스트
최근 다양한 머신러닝/딥러닝 기반의 모델들이 기업과 사회 문제 해결, 성과 향상을 위해 여러 분야에서 활용되고 있다. 이 책은 이러한 모델의 생애주기에 따른 효율적인 운영과 관리를 위해 MLOps의 기본적인 고려 사항과 노하우를 다루고 있다. 데이터 과학자뿐 아니라 데이터와 관련한 다른 직무를 수행하는 사람들도 최근 MLOps의 중요성을 크게 느끼고 있다. 이 책은 MLOps에 대한 기본 지식을 쌓고 다양한 사례를 확인함으로써 효율적인 머신러닝 운영을 돕는 디딤돌이 되어줄 것이다.
_김진엽, Visa, Visa Consulting & Analytics, 이사
머신러닝을 실제 서비스에 효과적으로 도입/운용하는 데 꼭 필요한 MLOps의 개념과 법칙, 역할과 구성 요소를 모두 담고 있다.
_김정민, 세이클, CTO













오탈자 등록
