IT/모바일
제공 : 한빛 네트워크
저자 : 한동훈
리눅스 커널은 인터럽트가 발생할 때 마다 do_timer() 함수를 호출합니다.
do_timer() 함수의 역할은 jiffies_64 변수값을 업데이트하고, 시간을 유지하는 기능을 합니다.
리눅스 커널은 부팅 중에 하드웨어 시계로부터 시간을 얻은 이후에는 자체적으로 시간을 관리합니다.
이 때문에 date 명령을 사용해서 시간을 수정하면 리눅스에서의 시간은 분명 바뀌는데, 하드웨어 시계의 시간은 바뀌지 않습니다. (물론 강제로 변경하는 것도 가능합니다.)
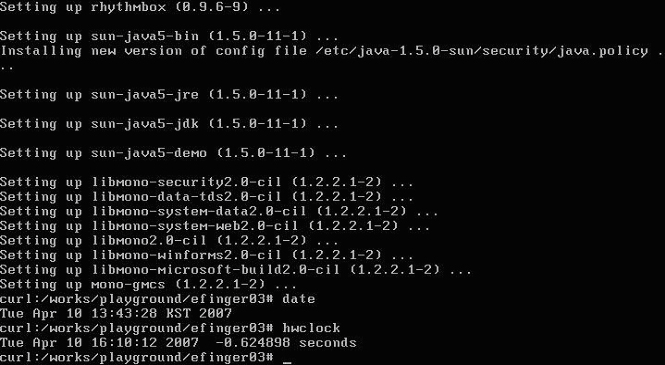
시스템을 최대절전모드에서 복원하는 경우 date 명령과 hwclock 명령을 실행해보면 두 시간의 차이가 확연히 생기는 것을 볼 수 있습니다. date 명령은 커널이 유지하는 시간을 보여주며, hwclock 명령은 시스템에 내장된 하드웨어 시계로부터 얻은 시간을 보여줍니다. 이 시간은 RTC(Real-time Clock)이라하며, hwclock 명령은 /dev/rtc를 읽어서 보여주는 역할을 합니다.
인터럽트는 HZ 상수에 정의된 값에 따라 발생합니다. 커널 2.6.20.4를 기준으로 보면 HZ 상수는 기본값이 250입니다. 이는 1초에 250번의 인터럽트가 발생하는 것을 의미합니다. 즉 4ms 마다 한 번씩 인터럽트가 발생합니다. 이는 최대 시간 해상도가 4ms이고, 이 보다 높은 시간 해상도 값을 얻는 것은 정확하지 않다는 것을 의미합니다. (jiffies_to_timespec() 함수를 이용한 나노초 시간, gettimeofday() 함수로 얻는 나노초 시간은 4ms 시간 해상도를 갖고 있으며 단순히 이를 확장한 값에 불과합니다.)
리눅스 커널은 인터럽트가 발생할 때마다 do_timer() 함수를 호출합니다. 즉 4ms 마다 한 번씩 호출해서 커널 내부의 시간을 업데이트합니다.
(커널 2.6.20.4의 소스)
시간을 정확하게 유지하는 것은 정말 어렵습니다. 컴퓨터 시스템은 전원을 넣는 순간부터 똑딱똑딱 자기 자신만의 시간이 흐르는 시스템입니다. 그러니까, 모든 시간은 해당 시스템의 전원이 들어간 순간부터 상대적인 것입니다. 인간은 자신이 속한 절대시간에 묻혀서, 모두 같은 시간을 보면서 살지만 컴퓨터 시스템만은 그렇지 않습니다.(아인슈타인의 상대성 얘기를 비유로 자주 얘기합니다만, 이해하는 분이 있는 건지는 모릅니다. :)
커널 2.6.14.6을 보면 update_times() 함수의 구현이 위와 다릅니다.
[참고]
수학적인 세상이라면 0.000001 * 1000000 = 1이 되어야하지만, 무수한 오차가 쌓여있는 것을 관찰할 수 있습니다. double result를 float result로 선언해보면 더 많은 오차가 생기는 것을 관찰할 수 있습니다. 줄줄이 달려있죠.
위와 같은 오차를 줄이기 위해 가장 일반적으로 쓰는 기법이 루프를 분할하는 겁니다.
처음 소스 코드의 실행결과와 비교해볼까요.
1.000000000007918110611627
1.000000000000006217248938
어떤가요? 오차가 확 줄어든게 보이나요? 여기서는 루프를 고작 백만번 반복했습니다. 이는 1 Mhz만큼 반복한겁니다. 1Ghz CPU라면 1초에 1,000,000,000번을 반복하는 겁니다. 이 클록의 간격일 일정하지 않다면 거기서 쌓이는 오차는 엄청나게 됩니다. 따라서, 결코 시간 측정을 위해 Hz를 사용하면 안됩니다. 만약, 사용하려 한다면 그에 따른 시간 보정 계획이 있어야 겠지요.
이러한 시간 보정이 완벽하다고 할 수 없습니다. 커널 2.6.20.4에 있는 update_times() 함수는 커널 2.6.14.6과 같이 직접 시간 보정을 하지 않고, update_wall_time() 함수를 호출합니다. 이 함수는 끔찍하게, 굉장히 어렵고, 긴 함수입니다.
이 부분의 소스 변경사항은 커널 2.6.14.6을 보면 update_wall_time_one_tick()에서 대부분 하던 것들입니다. 커널 2.6.20.4에서는 이런 동작들이 update_wall_time()이라는 새로운 함수로 옮겨졌고, 새로 작성된 부분이 많아졌습니다.
CPU 자체에서 발생하는 타이머 인터럽트를 로컬 타이머 인터럽트라고 합니다. 시스템 부하가 높은 경우에는 이 인터럽트가 발생해도 수행되지 않고 인터럽트를 무시하는 경우가 발생합니다.
CPU 자체에서 발생하는 타이머 인터럽트는 smp_local_timer_interrupt() -> run_timer_softirq()의 순서로 실행됩니다.
타이머 인터럽트는 연결리스트로 관리합니다. 보통, 저보고 타이머 인터럽트를 관리할 연결리스트를 구현하라고 한다면 연결리스트 하나를 만들어두고 “다 했어!” 라고 대답할 겁니다. 그러나, 타이머에 의해 발생하는 인터럽트 간격이 1초인 것도 있는가하면 10분이 걸리는 것도 있고, 1년이 걸리는 것도 있을 수 있습니다. 따라서 리눅스 커널은 발생간격에 따라 타이머 연결리스트를 5개 구현했습니다. 각각은 tv1, tv2, tv3, tv4, tv5입니다.
tv1은 1초이내, tv2는 1분이내... 이런 식으로 구현되어 있습니다. 앞에서도 말했듯이 CPU 로컬 타이머 인터럽트입니다. 즉 부팅시에 각 CPU 마다 하나씩 이 자료구조가 할당되는 것을 의미합니다. 보다 자세한 자료구조는 tvec_t_base_s 구조체를 찾아보기 바랍니다. tv는 타임 벡터(time vector)를 의미합니다. 부팅시에 할당되는 타임 벡터는 boot_tvec_bases 전역변수이며, EXPORT_SYMBOL()로 공개된 심볼입니다.
나중에 설명할 기회가 있겠지만(이대로 잊어버리는 경우도 종종 있습니다), 시스템에 있는 모든 CPU가 동시에 타이머 인터럽트를 발생시키는 것을 막기 위해 각각의 CPU에서 타이머 인터럽트는 약간의 시간지연을 두고 발생하게 되어 있습니다.
저자 : 한동훈
리눅스 커널은 인터럽트가 발생할 때 마다 do_timer() 함수를 호출합니다.
do_timer() 함수의 역할은 jiffies_64 변수값을 업데이트하고, 시간을 유지하는 기능을 합니다.
리눅스 커널은 부팅 중에 하드웨어 시계로부터 시간을 얻은 이후에는 자체적으로 시간을 관리합니다.
이 때문에 date 명령을 사용해서 시간을 수정하면 리눅스에서의 시간은 분명 바뀌는데, 하드웨어 시계의 시간은 바뀌지 않습니다. (물론 강제로 변경하는 것도 가능합니다.)
시스템을 최대절전모드에서 복원하는 경우 date 명령과 hwclock 명령을 실행해보면 두 시간의 차이가 확연히 생기는 것을 볼 수 있습니다. date 명령은 커널이 유지하는 시간을 보여주며, hwclock 명령은 시스템에 내장된 하드웨어 시계로부터 얻은 시간을 보여줍니다. 이 시간은 RTC(Real-time Clock)이라하며, hwclock 명령은 /dev/rtc를 읽어서 보여주는 역할을 합니다.
인터럽트는 HZ 상수에 정의된 값에 따라 발생합니다. 커널 2.6.20.4를 기준으로 보면 HZ 상수는 기본값이 250입니다. 이는 1초에 250번의 인터럽트가 발생하는 것을 의미합니다. 즉 4ms 마다 한 번씩 인터럽트가 발생합니다. 이는 최대 시간 해상도가 4ms이고, 이 보다 높은 시간 해상도 값을 얻는 것은 정확하지 않다는 것을 의미합니다. (jiffies_to_timespec() 함수를 이용한 나노초 시간, gettimeofday() 함수로 얻는 나노초 시간은 4ms 시간 해상도를 갖고 있으며 단순히 이를 확장한 값에 불과합니다.)
리눅스 커널은 인터럽트가 발생할 때마다 do_timer() 함수를 호출합니다. 즉 4ms 마다 한 번씩 호출해서 커널 내부의 시간을 업데이트합니다.
void do_timer(unsigned long ticks)
{
jiffies_64 += ticks;
update_times(ticks);
}
jiffies_64에는 인터럽트가 발생한 횟수를 기록합니다. 생각해보세요. do_timer() 함수가 실행된다는 것은 인터럽트가 발생했다는 겁니다. 그러니까 jiffies_64 변수의 값을 증가시킵니다. 그리고 시간을 유지하기 위해 update_times() 함수를 호출합니다.
(커널 2.6.20.4의 소스)
static inline void update_times(unsigned long ticks)
{
update_wall_time();
calc_load(ticks);
}
실제 시간 처리는 update_wall_time()에서 모두 수행합니다. wall time이라는 건 벽에 걸려있는 시간, 실제 시간을 의미합니다. 벽시계는 wall clock이라고 합니다. calc_load()는 vmstat, sar, uptime 등에서 보이는 부하 통계값을 갱신합니다.
시간을 정확하게 유지하는 것은 정말 어렵습니다. 컴퓨터 시스템은 전원을 넣는 순간부터 똑딱똑딱 자기 자신만의 시간이 흐르는 시스템입니다. 그러니까, 모든 시간은 해당 시스템의 전원이 들어간 순간부터 상대적인 것입니다. 인간은 자신이 속한 절대시간에 묻혀서, 모두 같은 시간을 보면서 살지만 컴퓨터 시스템만은 그렇지 않습니다.(아인슈타인의 상대성 얘기를 비유로 자주 얘기합니다만, 이해하는 분이 있는 건지는 모릅니다. :)
커널 2.6.14.6을 보면 update_times() 함수의 구현이 위와 다릅니다.
static inline void update_times(void)
{
unsigned long ticks;
ticks = jiffies - wall_jiffies;
if (ticks) {
wall_jiffies += ticks;
update_wall_time(ticks);
}
calc_load(ticks);
}
ticks는 시스템에 반영된 jiffies 변수와 실제 지피값(wall_jiffies) 값의 차이를 계산합니다. 이는 지피값을 보정하기 위해 사용됩니다. 인터럽트가 발생될 때 마다 do_timer()가 실행되고, 꼬박꼬박 jiffies 변수 값이 1씩 증가했다면 이런 보정은 필요없습니다. 그러나 리눅스 커널은 시스템 부하가 높은 경우 인터럽트를 무시합니다. 인터럽트에 의해 드디어 do_timer() 함수가 실행되면 그 동안 처리하지 못했던 인터럽트를 한꺼번에 처리하게 되고 무시된 만큼의 시간값도 보정합니다.
[참고]
#include실행결과 : 1.000000000007918110611627int main(void) { int i = 0; double result = 0.0; for( i = 0; i < 1000000; i++ ) { result = result + 0.000001; } printf( "%.24fn", result ); return 0; }
수학적인 세상이라면 0.000001 * 1000000 = 1이 되어야하지만, 무수한 오차가 쌓여있는 것을 관찰할 수 있습니다. double result를 float result로 선언해보면 더 많은 오차가 생기는 것을 관찰할 수 있습니다. 줄줄이 달려있죠.
위와 같은 오차를 줄이기 위해 가장 일반적으로 쓰는 기법이 루프를 분할하는 겁니다.
#include실행결과 : 1.000000000000006217248938int main(void) { int i = 0; int j = 0; double result = 0.0; double tmp = 0.0; for( i = 0; i < 1000; i++ ) { tmp = 0.0; for( j = 0; j < 1000; j++ ) { tmp = tmp + 0.000001; } result = result + tmp; } printf( "%.24fn", result ); return 0; }
처음 소스 코드의 실행결과와 비교해볼까요.
1.000000000007918110611627
1.000000000000006217248938
어떤가요? 오차가 확 줄어든게 보이나요? 여기서는 루프를 고작 백만번 반복했습니다. 이는 1 Mhz만큼 반복한겁니다. 1Ghz CPU라면 1초에 1,000,000,000번을 반복하는 겁니다. 이 클록의 간격일 일정하지 않다면 거기서 쌓이는 오차는 엄청나게 됩니다. 따라서, 결코 시간 측정을 위해 Hz를 사용하면 안됩니다. 만약, 사용하려 한다면 그에 따른 시간 보정 계획이 있어야 겠지요.
이러한 시간 보정이 완벽하다고 할 수 없습니다. 커널 2.6.20.4에 있는 update_times() 함수는 커널 2.6.14.6과 같이 직접 시간 보정을 하지 않고, update_wall_time() 함수를 호출합니다. 이 함수는 끔찍하게, 굉장히 어렵고, 긴 함수입니다.
static void update_wall_time(void)
{
cycle_t offset;
/* Make sure we"re fully resumed: */
if (unlikely(timekeeping_suspended))
return;
#ifdef CONFIG_GENERIC_TIME
offset = (clocksource_read(clock) - clock->cycle_last) & clock->mask;
#else
offset = clock->cycle_interval;
#endif
clock->xtime_nsec += (s64)xtime.tv_nsec << clock->shift;
/* normally this loop will run just once, however in the
* case of lost or late ticks, it will accumulate correctly.
*/
while (offset >= clock->cycle_interval) {
/* accumulate one interval */
clock->xtime_nsec += clock->xtime_interval;
clock->cycle_last += clock->cycle_interval;
offset -= clock->cycle_interval;
if (clock->xtime_nsec >= (u64)NSEC_PER_SEC << clock->shift) {
clock->xtime_nsec -= (u64)NSEC_PER_SEC << clock->shift;
xtime.tv_sec++;
second_overflow();
}
/* interpolator bits */
time_interpolator_update(clock->xtime_interval
>> clock->shift);
/* accumulate error between NTP and clock interval */
clock->error += current_tick_length();
clock->error -= clock->xtime_interval << (TICK_LENGTH_SHIFT - clock->shift);
}
/* correct the clock when NTP error is too big */
clocksource_adjust(clock, offset);
/* store full nanoseconds into xtime */
xtime.tv_nsec = (s64)clock->xtime_nsec >> clock->shift;
clock->xtime_nsec -= (s64)xtime.tv_nsec << clock->shift;
/* check to see if there is a new clocksource to use */
if (change_clocksource()) {
clock->error = 0;
clock->xtime_nsec = 0;
clocksource_calculate_interval(clock, tick_nsec);
}
}
보는 것 만으로도 눈이 핑핑 돌아갈 정도로 변했다는 것을 알 수 있습니다. 주석에 의하면 NTP(네트워크 타임 프로토콜)에서 얻어온 시간과 클럭 간격(clock interval) 사이의 오차까지 누적하고 있는 것을 알 수 있습니다. 위 소스에서 잘라보면 다음 부분입니다.
/* accumulate error between NTP and clock interval */
clock->error += current_tick_length();
clock->error -= clock->xtime_interval << (TICK_LENGTH_SHIFT - clock->shift);
NTP와 클럭 간격에 의한 누적 오차가 커지면 시간을 보정하는 데 적용시킵니다.
/* correct the clock when NTP error is too big */ clocksource_adjust(clock, offset);1 Ghz CPU가 있으면 1 HZ가 1 ns 마다 발생하니까 발생하는 클록수만으로 시간을 측정하면 어떨까? 라는 주제로 얘기를 한 적이 있습니다. 네, 실제로는 안됩니다. 첫번째 이유는 1 Hz가 발생할 때, 그 클록의 간격이 정말 일정하다고 보장할 수 있는가? 일정하지 않다면 무수히 쌓이는 그 작은 오차가 쌓여서 오차를 만들어내기 때문이라고 얘기했습니다. 두번째는 동적으로 CPU 동작 주파수를 변경시키는 절전기능이 탑재된 시스템에서는 그 정확성을 보장하기 어렵기 때문입니다. 물론, 현대 CPU는 펨토(10의 -15승)초 까지의 정확도를 제공하는 HPET 타이머를 제공합니다. 커널 2.6.20.4의 소스 코드를 보면 이런 고민들이 반영된 것입니다. 게다가, 주석에는 다음 버전에 변경할 내용까지 적혀 있습니다.
/* interpolator bits */
time_interpolator_update(clock->xtime_interval
>> clock->shift);
중간에 호출되는 이 함수는 지연된 시간을 보정하기 위해 사용됩니다.
이 부분의 소스 변경사항은 커널 2.6.14.6을 보면 update_wall_time_one_tick()에서 대부분 하던 것들입니다. 커널 2.6.20.4에서는 이런 동작들이 update_wall_time()이라는 새로운 함수로 옮겨졌고, 새로 작성된 부분이 많아졌습니다.
CPU 자체에서 발생하는 타이머 인터럽트를 로컬 타이머 인터럽트라고 합니다. 시스템 부하가 높은 경우에는 이 인터럽트가 발생해도 수행되지 않고 인터럽트를 무시하는 경우가 발생합니다.
CPU 자체에서 발생하는 타이머 인터럽트는 smp_local_timer_interrupt() -> run_timer_softirq()의 순서로 실행됩니다.
타이머 인터럽트는 연결리스트로 관리합니다. 보통, 저보고 타이머 인터럽트를 관리할 연결리스트를 구현하라고 한다면 연결리스트 하나를 만들어두고 “다 했어!” 라고 대답할 겁니다. 그러나, 타이머에 의해 발생하는 인터럽트 간격이 1초인 것도 있는가하면 10분이 걸리는 것도 있고, 1년이 걸리는 것도 있을 수 있습니다. 따라서 리눅스 커널은 발생간격에 따라 타이머 연결리스트를 5개 구현했습니다. 각각은 tv1, tv2, tv3, tv4, tv5입니다.
tv1은 1초이내, tv2는 1분이내... 이런 식으로 구현되어 있습니다. 앞에서도 말했듯이 CPU 로컬 타이머 인터럽트입니다. 즉 부팅시에 각 CPU 마다 하나씩 이 자료구조가 할당되는 것을 의미합니다. 보다 자세한 자료구조는 tvec_t_base_s 구조체를 찾아보기 바랍니다. tv는 타임 벡터(time vector)를 의미합니다. 부팅시에 할당되는 타임 벡터는 boot_tvec_bases 전역변수이며, EXPORT_SYMBOL()로 공개된 심볼입니다.
나중에 설명할 기회가 있겠지만(이대로 잊어버리는 경우도 종종 있습니다), 시스템에 있는 모든 CPU가 동시에 타이머 인터럽트를 발생시키는 것을 막기 위해 각각의 CPU에서 타이머 인터럽트는 약간의 시간지연을 두고 발생하게 되어 있습니다.
TAG :
이전 글 : 리눅스 커널 락을 없애려는 시도들
다음 글 : 왜 네트워크 디바이스 노드는 없을까?

최신 콘텐츠